Git/Mercurial vs. Subversion: Fight!
My esteemed colleague Chris Wong and I recently attended Joel Spolsky’s FogBugz 8 and Kiln World Tour event in Boston. Half the talk was a presentation of Kiln, Fog Creek’s new DVCS system built on top of Mercurial (hg). He came away from the talk with some strong opinions on what Mercurial (and its cousin git) really bring to the table. I thought I’d take a minute to discuss some of these arguments against git and hg:
Offline Version Control
Chris makes the point that switching to git or hg is an awfully big step for a single feature. Having spent five years traveling between customer sites with varying firewall configurations, network access policies, and government classification statuses, I can attest to the value of being able to work with an entire code base without relying on an internet connection. Telecommuting the past two years as a Comcast high-speed internet customer has only further rammed the point home.
Git/Mercurial is not necessarily DVCS
A lot of the remarks seem to focus on DVCS as a flawed concept, that really eventually reduces to CVCS once you actually start working with it. Indeed, on a small team, a single central repository is probably the most efficient means of sharing changes between team members. Once you start building the team out, however, the repository can be quite the bottleneck. When you want to design a larger scale workflow, you often find yourself bending over backwards to accommodate Subversion instead of Subversion accommodating you. Flexing the routes code must travel to get from one developer to another starts to become a lot more attractive. But if you still want a central repository (for example, you’re thinking of purchasing a hosted solution), both git and hg accommodate you beautifully.
Of course, there is such a thing as team branches, which brings me to my next point:
Branching and Merging in Subversion
Of course Subversion can handle branching and merging. So can CVS. And yet, the industry moved away from CVS to Subversion, citing easier branching as a reason for the switch. Branching pain is one of the most important cost differentiators in software development shops. It is at the very least worth a look.
svn:mergeinfo
Subversion merging improved substantially with the addition of a metadata tag called mergeinfo, which tracks revision numbers that have been merged into a given branch. This is a patch over an old problem of Subversion, to attempt to prevent SVN from merging the same changeset twice. Chris points out that git-svn (in its current version) does not correctly update this property during a merge. Valid point. But if one thinks of git-svn, not as a different version control system, but as a Subversion client, then his example serves to prove that there is inconsistent client support in the wild for svn:mergeinfo. On a large team, with developers using the best tools that make them the most productive, this property quickly becomes unreliable. Essentially, Chris’s argument reduces to, “As long as everyone just uses Subversion 1.6, Eclipse, and Tortoise SVN on Windows, we’ll all be fine!”
DVCS as a superset of VCS
Chris complains that by creating a superset of essential functionality, DVCS systems introduce complexity to a developer’s workflow, and creates more opportunities to make mistakes. Out of all his arguments, this is probably the one I have the most intuitive sympathy for. However, if one wants to do feature branching, it turns out the number of steps to feature branch in Subversion and git/hg are the same. I wrote up a technique in a prior post. The only thing git and hg make more difficult is the “cowboy” (commit to the head and forget) and “go dark” (go offline for months and then try to resync at the end) styles of development. That sounds more like a feature to me than a bug.
Subversion Roadmap
I’ll admit to my ignorance of Subversion’s roadmap. Looks like they’re hard at work implementing a lot of features that come standard with git and hg. You should keep in mind, though, that git and hg are not standing still either. They’re not just working to stay ahead of SVN; they’re also competing with each other, and the untold number of competing DVCS’s out there.
Hashes vs. Revision Numbers
Yes, integers are easier on the eyes than hashes. But when working with git or hg, you almost never refer to individual revisions themselves. Almost every changeset refers to a branch, which you name yourself. You can also tag till your heart’s content. Practically the only use cases for working with individual revisions in git or hg are reverts and cherry picks. I ask you Chris, which would you rather call a changeset, r4817:4907, or bug_383?
Subversion Bashing
Subversion is a terrific product, one I found myself in the role of championing for many years. Anyone “bashing” Subversion should be sentenced to 2 years working on a ClearCase project, which will make them appreciate just how much Subversion has done to advance the state of the art. But Subversion is no longer the state of the art, git and hg are.
Git-Svn and Remote Subversion Branches
I’ve been using Git for about two years now as my primary client for working with Subversion. Git offers me a number of advantages in my day-to-day work, including offline version control, fine grained feature branches, and the ability to package my change sets into single commits before distributing them to my teammates. I’ve found git-svn’s subversion integration to be quite fluid, and fits with the development workflow process I would use with any version control system.
For instance, here’s my workflow to work on bug X in Subverson:
#Fetch latest from SVN head
svn up
#Create a feature branch for X
svn copy $SVN_ROOT/$CURRENT_BRANCH $SVN_ROOT/$FEATURE_BRANCH
svn switch $SVN_ROOT/$FEATURE_BRANCH
#Commit changes on feature branch X as needed until ready to go
svn ci
#Return to original branch
svn switch $SVN_ROOT/$CURRENT_BRANCH
#Merge all changes on feature branch X, and collapse them into a single change set without committing
svn merge $SVN_ROOT/$FEATURE_BRANCH .
#Fetch any changes since last sync; add commit message as required by company policy
svn up
#Commit all changes to be sent; add commit message as required by company policy
svn ci
Here’s the same workflow using Git-Svn:
#Fetch latest from SVN head
git svn rebase
#Create a feature branch for X
git checkout -b X
#Commit changes on feature branch X as needed until ready to go
git commit -a
#Return to original branch (master)
git checkout master
#Merge all changes on feature branch X, and collapse them into a single change set without committing
git merge --squash X
#Fetch any changes since last sync
git svn rebase
#Commit all changes to be sent to SVN; add commit message as required by company policy
git commit -a
#Push changeset to SVN
git svn dcommit
Note that Git only needs a connection to the remote repository for the rebase and dcommit steps, while Subversion requires a connection for all version control operations. Git also handles the merge operation in the latter case. So far so good.
The most difficult part of working with Subversion from Git is managing remote branches in the repository. The key is to create a remote branch in Git for the branch itself, and then a local Git branch to track that remote branch. Let’s say you have a release-1.0 branch to track fixes to the 1.0 version of your product. This might appear in your Subversion repository as:
$SVN_ROOT/branches/releng/release-1.0
You can add remote branches as you need them with git-svn:
#Tell git-svn where to find the new branch:
git config --add svn-remote.newbranch.url $SVN_ROOT/branches/releng/release-1.0
git config --add svn-remote.newbranch.fetch :refs/remotes/newbranch
#Fetch the remote branch from Subversion
git svn fetch newbranch
#Create a local git branch to track the remote branch:
git checkout -b local-newbranch -t newbranch
git svn rebase newbranch
Now you can jump back and forth between the trunk (master) and the release branch as much as you need to. Since fetch and rebase will import all changes made to each remote branch, you can also use git to handle merges between the branches as well.
Thanks to this post from Stack Overflow for the succinct steps for adding a remote branch.
Core Committers
I work in Boston, where the average Java programmer makes approximately $100,000 per year. In small companies, coders are often the single highest expense a company will incur. It is therefore in the best interest of the firm to ensure that this cash ultimately flows toward working software. As Joel points out, the primary function of a great software company is the conversion of cash into code.
As your team grows in numbers and your system grows in complexity, you are bound to discover that it gets easier and easier to introduce critical bugs. New team members will repeat mistakes that the original authors made years ago; reintroducing old problems. Programmers with incomplete knowledge of the code base can make decisions that seem correct on a micro level but do not make sense on a macro level. And the technical leadership will grow more and more frustrated at seeming to solve the same problems over and over again.
How then, to make sure new team members are not re-introducing old problems into your code base, and thus defeating the purpose of bringing them on in the first place?
Solution 1: Restrict access to version control to core committers with complete knowledge of the code base.
Let’s assume for the sake of argument that you can identify 2-3 people who can decide, unfailingly, whether or not a given code change will have any adverse affects whatsoever. Each one will be promoted to a new job title, perhaps technical architect, developer manager, or what-have-you. All other developers in your organization must submit changes to this core group for review. The committer then accepts or rejects each submission. Accepted submissions are checked into the code base, rejected ones are not. This approach is quite common in open source projects with large communities of contributors, where the volume of submissions is so large that it is impractical to make everyone a committer.
In a smaller development shop, however, this approach has a few drawbacks. The core committers are also often the strongest developers in the organization. Rather than writing and re-factoring code, they spend a large part of their day reviewing submissions. So your strongest coders are not writing code, and conversely, weaker coders write almost all of your new code. New feature counts decline; bug reports and Daily WTF submissions go up. More bugs and less features means the cost of each new feature has gone up on the balance. There’s also a new bottleneck in your organization; features can only be introduced when a committer has the time to review it.
Responsibility for the health of the code base has also changed; at least individuals’ perception of it. The committers are now completely responsible for the quality of the code base, while the developers are now liberated from it. Developers that feel no responsibility for the long term affects of their code don’t take the necessary steps for long term code base health like adding comments, re-factoring for legibility, and writing unit tests. The committers of course can yell and scream and beat the developers with reeds, but again, the overall cost of new code has gone up.
You’ve also just identified the largest internal threat to your company’s survival. People leave for better offers, start families, get hit by buses; pick your favorite PHB metaphor for losing a key team member. When it comes time to replace one, you face the onerous task of replacing someone motivated by quality and bug prevention with someone who has spent the past X years writing code with little ownership in the final product.
But I think the largest issue with this solution is the implicit assumption that people with complete knowledge of the code base exist. Any system of non-trivial size is too large in size in scope for any one person to hold in his or her head all the potential implications of any design decision, even the system’s original authors. Once more than a few people contribute to a code base, it very quickly becomes impossible to keep track of all the changes that are going on. The difficulty of accepting that you no longer completely control your own creation is one of the biggest reasons this solution is so popular in mediocre companies.
Solution 2: Re-factor the system’s design to separate out individual functions and allow a common vocabulary throughout all components. Divide developers into teams to work on individual functional areas.
Instead of locking down control, you gather the strongest coders together and work to re-factor the system into functional areas. In a banking system for instance, one team might be responsible for account summaries and transaction reporting, one team might be responsible for transfers and payments, and still another might be responsible for processing loan and account applications. An interfaces team could design a uniform manner of exchanging results between these systems, and a core model team could own the structure and format of stored data. Now each strong developer can recruit team for implementing new features.
Now each team is collectively responsible for a functional area together. In effect, you have divided a large, complex system into smaller, more manageable components. The team manages quality within their boundaries, and interfaces are designed and tested collectively by the leads. The key difference now is that developers take more ownership over their decisions; they are the ones who must deal with their own coding decisions. They can fix mistakes as they discover them, add comments and unit tests, and still roll in new features. Your money is being converted into code without the control bottleneck of a few elite.
Of course, it’s still possible for a developer to introduce a bug. I’ll go further than that: every developer will eventually. So quality must be monitored for he whole system at a level beyond what a human can keep in his or her head. This is where your unit tests, peer review, and continuous integration system come into play. Unit tests defeat the O(n^2) problem of regression testing. Anyone who has worked on a section of code for more than 6 weeks has struggled and learned enough to carry out a worthwhile code read. Your CI will find more bugs in a week than a core committer will in two months. But even with all this QC, it is still possible for bugs to leak out. Deal with it. You must have an error reporting system and a process in place to roll out critical fixes before releasing any version of your system. Be honest with your customers about the possibility of problems, and transparent about your resolution processes.
When your programming resources are your largest expense, you want to get the highest output possible from your investment. You are turning cash into working software. Re-factoring does more than just improve readability; it can help reduce coupling to the point where individual areas can develop and grow organically. The smaller in scope each functional area, the higher quality it will become, and as a by-product, the higher quality your entire system will become. Don’t be afraid to let your fledging system grow into a mature one. Mature systems are stable, and ultimately more profitable.
Design by Committee Recursion
Trivia question: How many different ways can one answer a true or false question?
Let’s answer this question with a simple thought experiment. You have been hired as the lead architect for the design of a brand new workflow processing solution for Incorporated Dynamic Innovations of Technology, LLC. At your fingertips are all the latest technologies. You waded through weeks of phone interviews to identify the crack team of hackers that will build out the new platform. The first item on the agenda is to capture whether a user has interviewed a subject.
Design problem: Create a form field to indicate whether a subject has been interviewed.
As design problems go, this is a softball. “Ha!” you say. “Easiest problem in the world. I’ll create a checkbox which will indicate whether the interview has happened yet or not. Time for happy hour!” And so, over the course of an overnight marathon of pizza, Mountain Dew, and Nintendo Wii, your crack team writes out your checkbox.
Solution #1: Checkbox: Checked => true, Unchecked => false
A few weeks into testing the analytics design team comes into your office with a problem. They’re having trouble deciding whether an unchecked field means that an interview definitely hasn’t taken place, or whether the user didn’t know if an interview had taken place. You can’t verify that a user has actually thought about the value for the checkbox; whether it’s checked or unchecked, it’s still valid as far as the system is concerned. “Okay no problem,” you say. “Instead of a checkbox, let’s have the user say yes, the interview took place, or no, the interview did not take place. That way, we force our user to think it over and make sure the right data goes in.”
Solution #2: Create a radio button with two values: true and false.
Whew, dodged a bullet there. Now we know for sure, in all cases, whether the interview has taken place! But beneath the surface, a nefarious complication has been introduced. There is now a possible third answer to this question: neither true nor false. Explicitly, there are two options: true and false. But semantically, there is a third implicit option: unknown. Now it turns out that part of the mission of IDIOT LLC’s new platform is to feed data into a warehouse for large scale data mining and analysis. The analytics group is a team of ex-MIT researchers who are well aware of the difference between false and unknown, thank you very much. They want all partnering systems to flag each inbound record with true, false, or unknown, since they can’t be assured that all systems are capturing this data in the same way. So as the architect, you note a business rule that a missing value for our data element represents an unknown. The system interface is turned on, the data starts flowing, and everybody’s happy.
Skip ahead a year or two. Organization wide, IDIOT LLC has had its share of low profile project failures and perhaps one or two high profile ones. Meetings have been held amongst the executive leadership to identify ways to improve data quality. In particular, there seems to be an unexplained source of error in the analytic reports. Our humble data element is captured by several systems, which feed into the warehouse. Some systems require a true or false value, and some do not. But all systems report a missing value as unknown. The root cause of our data quality problem seems to be that unknown includes cases where a lot of users simply forgot to add the value. The CIO stands up and says, “This is going to come to a halt, gosh darn it.” All users will now have to explicitly state, in all partnering systems, if the interview has occurred, if the interview has not occurred, and if the user simply doesn’t know. As the architect, you grudgingly accept the order from on high, and modify your solution accordingly:
Solution #3: Drop-down box to capture true, false, or unknown
But now we’ve come back to the same problem we started out with. There is a semantic difference between someone expressing unknown as a value (explicitly unknown), and someone opting not to provide a response (implicitly unknown). With three explicit values, we’ve implicitly created a fourth value for our humble true/false question: implicitly unknown. So we have three explicit values (true, false, and unknown) and a brand new implicit value (implicitly unknown).
But this is absurd, right? I mean, there isn’t a real difference between “unknown” and “forgot-to-answer,” is there? Well to a human being, not really. But to a computer, or a large, interconnected network of systems, there is a very real difference. And indeed, eventually, this new implicit option can be encoded into data exchange formats as well. A colleague mentioned to me yesterday a new requirement from a customer that four values for a true/false question be captured in a report: true, false, explicitly unknown, and implicitly unknown!
We started out with a simple data element, true or false. We went off the reservation once we started trying to guess the user’s intent through a combination of what the user did and did not do. Is the statement false? Does she really not know, or is she expressing that she is certain it’s false? It’s not unlike a fourteen-year old girl trying to guess whether the cute boy in her biology class likes her by just how brusquely he pushed past her in the lunch line (actual reason: french bread pizza day! Sweet!). The other side effect is that with each new recursive slice we add into our true/false data element, we dilute the value of the original data element. (How much could it possibly matter whether something is explicitly or implicitly unknown? In either case, you still don’t know!!!)
The correct answer to my original question, of course, is that there are infinitely many ways to answer a true or false question, just as there are infinitely many numbers between 0 and 1. Only a human being can tell where the line in the sand belongs; the committee will never get to that point.
Completely Unqualifed Opinion: Google Chrome
My girlfriend and I spent this past weekend in Ann Arbor, Michigan to catch the UM home opener (and loss, unfortunately). One of her classmates grew up in the area, and her family was incredibly generous in letting us stay with them while we were in town. Over dinner Friday night my host asked what I do for a living, and as always, as soon as I said “Software Engineer,” he asked asked if I could fix their computers for them. I don’t begrudge such requests quite like some of my peers do, but in this case I was especially eager to repay my hosts’ hospitality, and quickly agreed.
The family had a desktop computer and a laptop with a whole mess of virus and adware mucking up the works. The desktop was infected with Antivirus 2009, rendering Internet Explorer completely useless. I’ve done this enough times to have a fairly set routine:
- Download and install Mozilla Firefox
- Download and run AVG Antivirus (Free version)
- If necessary, download and run Ad-Aware (Free version)
I’ve found that works in plenty of these situations. After I was finished, I left Firefox behind on the laptop, purely by accident. Later, the laptop’s owner thanked me for installing it, saying he had heard of Mozilla, but didn’t know how to get it. Typing “Firefox” into a Google search had honestly never occurred to him.
This experience stayed with me as I read today’s news that Google is launching a new web browser called Chrome. Ostensibly, this is an attempt to improve the experience of its web-based offerings by taking more control over the desktop environment. If Google’s offerings can only be used through a browser, then Google naturally has a vested interest in making sure the browser is lean, fast, and stable. By jumping into competition with Firefox and IE, Google can either a) grow and become a dominant browser or b) push Microsoft and Mozilla to advance their products and see Google’s web products improve from the user’s perspective as a natural by-product. It would appear that Google is making a move on Microsoft to push the desktop operating system into irrelevance.
TechCrunch certainly seems to think so. In fact, the author goes so far as to suggest that Google is attempting to supplant Windows itself:
“They’ve built their own Javascript engine [V8] despite the fact that Webkit already has one. This should make Ajax applications like Gmail and Google Docs absolutely roar. When combined with [Google] Gears, which allows for offline access (see what MySpace did with Gears to understand how powerful it is), Chrome is nothing less than a full on desktop operating system that will compete head on with Windows.”
They may be on to something here. I pulled the latest market share data for browser share:
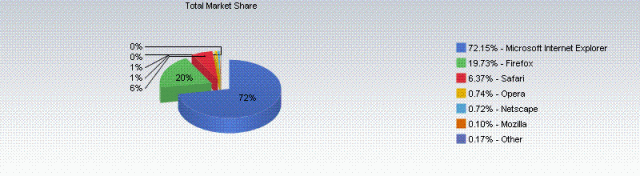
Browser Market Share: Courtesy of Net Applications
and for operating system share:
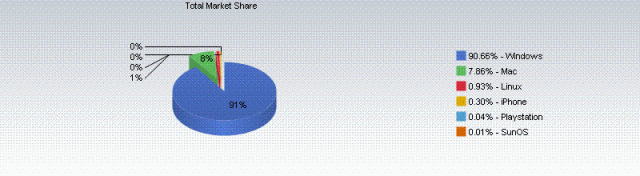
Operating System Market Share: Courtesy of Net Applications
Firefox, the fastest growing browser, will soon claim 20% of the browser market. IE’s market share still tracks pretty closely with the installed user base of Windows, which while declining, is still clearly dominant.
I wonder, however, what piece of this pie Chrome will cut into. A lot of times unabashed nerds like myself tend to forget that most average people couldn’t care less what web browser they use; they’ll use whatever the computer comes with (Read Nudge for some sciency explanations why). My young friend I mentioned earlier is illustrative: a lot of people don’t know or don’t care to find out how to install new browsers (and other programs for that matter). Firefox only comes installed by default on a few platforms; for any others a user must explicitly decide to go to Mozilla and download it on their own for Windows, Mac, and more than a few Linux distributions. So in the browser space, really the piece of the market that’s open to newcomers is the 20% occupied right now by Firefox, Opera, and the rest. The threat here is that Google could cannibalize the usage volume it gets from its prominent placement in Firefox (the home page and the default search).
If Google’s eye really is on unseating Windows, releasing a competitor to IE is not going to be enough. Internet Explorer is still “the Internet” to the vast majority of computer users, and will be until Microsoft’s defaults change or the underlying reality of the operating system market does. Windows’ market share has been in decline, much to the benefit of consumers, thanks to Apple’s resurgence and increased public awareness of open source products such as Linux. This has had the dual benefit of improved user experience (and expectations), while forcing operating systems to at least pay lip service to common standards. In this new competitive landscape, a Linux distribution designed, developed, branded, and supported by Google would be in a far better position to finally knock Windows off its lofty perch.
So where is the Google OS? Android is only a few months from landing in US consumers’ hands, can a true, ad-supported Windows killer be lurking behind the curtain? Until then, new browsers won’t change the basic math of the browser competitive landscape, they’ll just duke it out for the leftovers. I expect to see Firefox and Opera’s numbers decline as Chrome gains market share; there’s nowhere else for Chrome’s users to come from.
Why Wait for a New Release of JIRA?
Why Wait for a New Release of JIRA?
At my company, we rely pretty heavily on our feature/bug tracking system, JIRA. All of our customer requests are logged and tracked there, as well as any internal problems or handy little improvements we come up with. Each week, we gather around the old conference call phone and hash over a list of issues that have been added/updated since our last chat. The system works great; its a really nice way to keep everyone in the loop on whats going on across 2+ offices and 2+states/countries. And it can usually be done in 1-2 hours.
JIRA is web-based, and typically the call host will open the week’s issues in browser tabs. Sometimes the presenter has set up a browser in advance, and sometimes even done something as fancy as set up an RSS (one click -> all the tabs open up at once!) But more often than not the first 2-3 minutes are eaten up by the presenter right clicking and opening each of about 40-50 issues into a new tab. It doesn’t make for engaging conversation. It also looks like you’re chronically underprepared if you decide to use the same great idea for discussing issues with customers….
Enter Greasemonkey. Greasemonkey is a framework for running your own browser Javascript on any web page you can get to through Firefox. The semantics are the same as if you were writing javascript on the server side; it’s code that gets run by the browser after an HTML page has been downloaded and rendered. Perhaps Greasemonkey can help us out here…
JIRA issues are tagged with a project code (example here is JIRA), followed by a sequence number. Each issue can be fetched via the URL /jira/browse/JIRA-999. If I were a JIRA developer and was asked to implement this feature, I could write a simple javascript loop to open all these links in new windows (not all browsers support tabs, and believe it or not, not all users use tabs; best to let their preferences decide how to open all these links).
So here’s such a loop in javascript:
function openIssuesInTabs() {
var anchors = document.getElementsByTagName( 'a' );
for( var i = 0; i < anchors.length; i++ ) {
if( anchors[i].href.match( \'/jira/browse/\' ) != null ) {
if( anchors[i].href.match( anchors[i].innerHTML ) ) {
window.open( anchors[i].href );
}
}
}
}
I’m not terribly concerned with performance at the moment; we’re just getting started. All this loop does is find all links matching the pattern identified above: that the URL is correctly formatted, and the inner HTML text matches the anchor URL. There are a few duplicate image links; this check makes sure we only open one tab per issue.
But of course, we need a way to trigger this loop somehow. It makes little sense to pop open tabs every time; the result page would become useless. We can use a little more Javascript to render a link on the search result page:
var permLinkDiv = document.getElementById( 'permlink' ).parentNode;
permLinkDiv.innerHTML = ' \ [ <a id="openTabs" rel="nofollow" onclick="javascript: \
var anchors = document.getElementsByTagName( \'a\' ); \
for( var i = 0; i < anchors.length; i++ ) { \
if( anchors[i].href.match( \'/jira/browse/\' ) != null ) { \
if( anchors[i].href.match( anchors[i].innerHTML ) ) { \
window.open( anchors[i].href ); \
} \
} \
}" href=" ' + window.location.href + ' ">Tabs</a> ] ' + permLinkDiv.innerHTML;
This little snippet will render a text hyperlink next to the “Permalink” navigation control on the search result page. The location is actually arbitrary; there’s nothing to stop me from rendering it elsewhere on the screen. I just picked a link that the JIRA developers were kind enough to add an “id” attribute to. Note that I’ve set the script as the onClick attribute, and the current page as the href. This will make sure the source window remains on the same page after I spawn my tabs.
Installing the greasemonkey script involves adding it via the Greasemonkey Firefox plugin. The plugin requires that you specify a match string so it can tell what pages to run your script against. I can add the domain of our issue tracker, and the name of the search results page as the match string. Now when I open the search results page in JIRA, I see a “Tabs” link rendered within the page (CSS consistent, too!) Click on the link and viola! A neat collection of tabs for all issues listed on each search result page.
But how can I share this goodness with my teammates? Easy. A free compiler exists to compile your Greasemonkey script into a Firefox extension. It’s limited to a single browser (Firefox), but a Greasemonkey script could only be run within Firefox anyway. The compiler emits a *.xpi file formatted for Firefox. My teammates need only open this file in Firefox to install it. They don’t even need to install Greasemonkey!
Ahhhh… now if only I could make these calls more interesting….
Quality Assurance
After the New Year my current project entered its testing phase. I wrote in my last post that my QA policy was an Excel spreadsheet with check marks. That’s exaggerating slightly, but I’ve learned very quickly that our first couple attempts didn’t work too well.
There’s been two issues that quickly spring to mind:
Reappearing bugs
We’ve had some success managing change requests with our issue tracking system. The flow goes like this: a tester has a problem with the interface or something breaks, and enters the issue into the issue tracker. Our business analyst vets the issue against our current specification. Change requests are logged as meeting agenda items; spec violations are assigned to me. I either fix the bug myself or assign it to the responsible developer. The bug is fixed, and the business analyst verifies it has been fixed on our test server. So far so good.
What the consultants and best-sellers don’t tell you is that bugs have a nasty habit of re-breaking. A bug tracker can tell you that a bug was fixed at one point in time, but it has no information as to whether a bug that was fixed two months ago is still fixed. Software components behave in ways that are difficult to predict when integrated together. Poorly designed components also tend to crumble as features are added to them as well; about 75% of our reopened bugs were the handiwork one bad developer. To make matters worse, most of these bugs are user interface issues, which are both highly visible to the customer and difficult to unit test.
I’ve tried two approaches to this problem. The first was more of a punitive measure against my special egg: I had him print out his bugs from the past four weeks and verify that all were still fixed. This wasted a lot of my time and his, but it certainly slowed the re-emergence of bugs. The better solution I believe is to have a robust set of automated tests. Selenium is a open-source javascript test script suite designed specifically for rapidly generating and updating user interface tests. I use the Selenium IDE to record a user session, export the test as a junit test, and add it to my regression test suite. My Cruise Control build server can open a web browser and execute all tests within on every check-in, providing a much higher level of confidence that bugs are staying fixed.
Version Control
And by this I mean product version, not source control. In the beginning there was my development machine (read: laptop). Testers needed a server to hit without disrupting my work, so we set up a demo server with the latest HEAD build from my box pushed out at regular intervals. My client’s staff needed instances against which to develop reports and train on configuring the final product, so an internal release server was set up for them to download a copy to their workstations. This week we began setting up an external test and training sandbox for our first group of users, a performance and load testing internal server, and the production environment will be available any day now.
That’s a lot of copies of my application floating around. It’s particularly problematic when addressing bugs, since the bug can only be reproduced on the version that user is using. Who’s using what instance on what machine? Which log files do I check? Asking users to record their version in the issue tracker is an imperfect solution; folks are human and very rarely put more into the issue tracker than a title and a summary. Is there a better solution?
Cruise Control is riding to the rescue here as well. Once a build passes our test suite, it’s published to each environment. The internal distribution server points at the new build when client staff needs to train, the testing, demonstration, and load test servers all get copies of the new build, and the build is tagged in version control as the latest build to pass our QA tests. As for production, my idea here is to have a staging area that new builds are pushed to automatically, and then a technician can hand copy them to the production application server at a suitable time. All environments now have the same build.
Right now I’m a “project lead” on a system in the QA phase getting ready for user acceptance testing and pilot roll out. I put project lead in quotes because I sort of fell into the role after being hired; really you can’t call me more than a Java developer.
I tried to focus mainly on topics I’m already interested in, such as productivity enhancements , plus get a few insights and ideas to help me through the QA process. Here’s a short list of the things I learned this weekend:
I really need to go out and get a MacBook Pro.
I’m quite certain Mr. Jobs and Co. don’t need any more raves about their products, but damn. All but one of the presenters at this conference use MacBook Pros as their tools of choice; all presented using the same machines they use for day-to-day development. The lone Windows user wrote every one of his demonstration code samples live in front of the audience using Windows Notepad, and must have hit the Backspace key about 5 times during an 1.5 hour talk. Barring any other freaks of nature out there, the gains from Mac OS X are staggering.
The clincher for me was Neal Ford’s talk on productivity. He demoed a small application on his MacBook called QuickSilver. To use his words, its a graphical command line. Nothing like this exists for Windows. With a series of simple keyboard gestures you can choose 3 files from separate hard disks, zip them together, and email the target to a recipient. Astounding.
Productivity gem: Mac OS X stores the keyboard shortcuts for every open application in the same place, and displays a cheat sheet based on whichever is active.
As soon as the funding gets lined up, I’m hitting up the Apple Store.
I really, REALLY need to install IDEA
I can’t cry poverty in this case, since my boss has generously offered me a floating license for IDEA whenever its convenient for me.
I first heard of IDEA at my first job, circa 2004. Due in part to cost and part to customer policies, we were restricted from running IDEA as our development machines. My mentor and tech lead would occasionally wax poetic about his salad days using IDEA for all his development, constantly ranting about how “slow” Eclipse was, and constantly looking for a somewhat decent JSP plugin.
Fast forward to today, when I’m one of two developers at my small ISV running Eclipse full time. When I first started a year ago, I thought I would stick with what I know, since it would be one less thing to spin up on. I got used to the idea of waiting 6 minutes for my incremental builds. I didn’t think a good JSP editor/debugger existed that could seamlessly integrate with an IDE’s method implementation and invocation lookups. Oops.
One more little productivity gem: IDEA will actually train you to use its keyboard shortcuts. If you use the same command three times, it will recommend you to create a keyboard shortcut if none already exists.
One of those things were, once you see them side by side, you can’t believe why any sane person would ever pick the first over the second.
We should have started QA much sooner
We used continuous integration at my previous company in a bad way. Sure we had a Cruise Control server running, but if all it does is check if the build completes successfully, it’s basically a glorified compiler.
But you can incorporate:
- Junit Tests
- Selenium Functional Tests
- Cyclomatic Complexity Reporting with JavaNCSS
- FindBugz static code checking
- JDepend dependency analysis
….and produce a ton of useful metrics about the overall health of your code base. You can’t catch everything, but you can catch a lot.
Unfortunately the underlying assumption here is an Agile development process with unit tests written as code is developed. Yea, we’re not quite there. Our “regression test” is an Excel spreadsheet with check marks, and that only came about after testers began complaining that previously closed bugs were reopening. Not really something you can automate. However, thanks to Selenium, we can at least automate our regression tests, even in the absence of more robust unit testing. You really shouldn’t re-factor to include unit tests, but better a repentant sinner than a self-righteous preacher.
As the industry (well, the hype anyway) trends toward dynamic languages like Smalltalk, Ruby, and Groovy, its going to become nearly impossible to ship code without a full suite of unit and regression tests. It’s just too easy to get your code to run, and bad developers just don’t care if their code passes tests or not. Particularly temp developers (there’s no such thing as a good temp developer). Even good developers cheat here and there when it comes to pure test driven development, especially with programs that are notoriously difficult to unit test (we’re looking at you, Struts!) This is a very, very, very good thing. I do not want to ever end up in this scenario again, and preventing it is motivation enough to pick up one of the Groovy books on the way out the door.
Best quote: “This will be the year of spectacular Ruby on Rails failures.”
One language just ain’t gonna cut it anymore
Speaking of buzzwords, you couldn’t fart without some windbag going on and on about how totally cool Groovy is. “Look! Hello, World in just one line!” My humble opinion is that the text representation of code is far less important than the bytecode; your audience here is another developer looking for bugs, not a fashionista. Groovy fails on both counts; the compiled Java byte code for a 10 line Groovy script runs about 5k, and the code samples I saw looked like the bastard stepchild child of c++ and python.
But a recurring theme was definitely the increasing specialization of languages. A language for scripting (Groovy), presentation (JSP), user interface (Swing and AJAX), database access (SQL), prototyping (Jython), rails (JRuby), multi-threading (Scala and Jaskell); all running using Java bytecode over the Java Virtual Machine. Combine this with the open sourcing of Java, and you have the emergence of Java as an assembly language for the Java Virtual Machine.
The JVM has existed for 12 years now, and despite the ever-present noise from its religious objectionists, it is a fast, stable, and secure platform that has survived a decade of trial by fire. It has maintained dominance in the software industry longer than its predecessor, C++. Yet the newsgroups all continually complain about Java’s “limitations”: no (direct) support for function pointers, rigorous type checking, vebosity. The constant whining has led to scope creep in Java itself. Take generics, which require type-safety when declared, but do nothing to enforce safety in their contents. Silly me who thought that was the whole problem in Java Collections that needed solving. Many features like this have crept into Java and are hardly in use anywhere.
But plain old Java is a well understand language. If someone puts Java code in front of a Java developer, chances are that developer can deduce its function given enough time. But if you did the same thing with Haskell code, the developer could probably figure it out, but you can be darn sure the first case would be easier. So what if you could compile your Haskell into Java? And use a Java debugger/profiler? And deploy it immediately to the millions of JVMs currently running on user and enterprise machines?
You don’t need generics or closures or autoboxing in Java itself. If Python takes less time to write, write Python and compile it to Java bytecode using Jython. Java itself is going to become less and less used by developers, and instead become a compilation target. So Java itself is now becoming a metaphor for JVM behavior, which is a metaphor for machine behavior.
*I plan to write about the work I do for my company a bit in this space, but until I talk it over with the company’s founders, I’m going to keep my company anonymous. I would very much like to increase our exposure by mentioning it in this space, but they reserve the right to stop me.
I work here in Boston for a small ISV (to use Eric Sink’s parlance). Our product is a tabula rasa J2EE case management system. One feature of our system is an import/export tool, that allows a single case to be imported and exported to/from a standard XML format. We get all sorts of feature gains from this:
– Web Services data exchange capability
– Archiving
– Database memory usage management
It’s also enabled a spectacular way to create a robust testing harness. We have unit tests for features such as log in, opening / closing cases, modifying reference data, etc. that belong to the core application. However, writing unit tests for each individual customer could theoretically cost a lot of cycles in implementation.
On my current project, test pre-conditions and post-conditions typically come in the form of an Excel spreadsheet from our BA. Personally I love Excel; I think it’s one of Microsoft’s real accomplishments that succeeded on its own merits rather than lock-in. BA’s love Excel because its an easy way to organize a table of information.
Well a test pre-condition is simply an import file! All our unit tests begin by importing a case into the application. Similarly, all post-conditions should be observed if the case were exported immediately after processing. So our unit tests capture the result case via export. The process is generic enough that a baseline abstract unit test can cover all generated test cases. So the script writes a JUnit .java file with test() methods based on the output columns.
So if each class of tests can be described in an Excel spreadsheet, then a simple framework to parse a spreadsheet, produce a “before” case import file, an “after” case file, and a JUnit .java file for each row can handle most of the end-to-end testing we’ll need. Advantages to this approach:
1. Extensibility – Each spreadsheet contains a class of tests. Adding new unit tests is as simple as adding a row to the spreadsheet and running a script.
2. Maintainability – Instead of the development staff maintaining each individual test, the Business Analyst has complete control over each class of tests, and can be provided a report on which tests passed and failed. And he/she gets to use Excel!
3. Accountability – I assume JUnit testing needs no justification to today’s developers. But its nice to be able to have the Business staff back you up when you claim your system is functioning according to spec. And your client has a little more evidence than just your word that the system is working.
4. Versioning – Since the spreadsheets are the driving force, those are the only files that need to be checked into version control. This is nice if your client insists you use an obtrusive KM system like Sharepoint.
I’ve been using this approach for several weeks now, and have a suite of about 700 unit tests. That’s built from two spreadsheets, about 160 rows each. So far it seems to be running pretty smoothly. The difficulties lay in writing the initial script, and making sure the BA gives you a parsable Excel file (instead of a two-column, id plus semicolon delimited string format).
Who are you?
I’m a software developer, consultant, mentor, pupil, leader, son, brother, friend, Catholic, sinner, amateur poker player, Tae Kwon Do-ist (for lack of a better term), and bad writer (I’m working on that last part…)
What do you want?
I want to competently turn cash into great software. I want to recruit and organize the building blocks of a great company (the people). I want to retire with 2.5 million dollars at the age of 65. I want to be the best husband, father, brother, and son to my family. I want to finally earn a black belt in Tae Kwon Do six years after I started.
I thought this would be a good way to start out a new blog. I’m fully aware that most blogs suck, and it will be a while before this one catches any eyes. I have, however, come to realize two facts about my personal and professional lives.
One, two years of graduate school and two years of work as a contract software developer has all but destroyed my communication skills. This job just doesn’t lend itself to social growth. Without training, social and communication skills erode just like physical skills do. As an exercise, every programmer ought to try to explain the tasks for the week to a random layman at the job site; the further removed from technology the better. The division sys admin could work for a start, the lobby secretary is a better challenge. With time and practice, eventually you can try a project manager. That last one isn’t for the faint of heart.
Secondly and less melodramatically, blogs are without a doubt a powerful networking and professional development tool. We engineers wrestle with new problems each and every day, and perhaps I can contribute a thing or two to the community at large. We’re also notorious for slamming each others’ work. But I’m not one to back down from the harshness of public rebuke, so I’ll post some of the challenges I come across, and some of the solutions, and offer them up for cruel review. At worst I’ll come of as incompetent; at best I’ll find some new insight into my work.
I also want to have fun with this. So slam my attempts at comedy, too!
About

I’m a developer with a small but exciting company in the Boston area called LifeIMAGE. We’re trying to put medical images into the hands of patients and care-givers anywhere, at any time.
Please leave comments!
-
Archives
- October 2010 (1)
- May 2010 (1)
- May 2009 (1)
- April 2009 (1)
- September 2008 (1)
- June 2008 (1)
- March 2007 (2)
- November 2006 (2)
-
Categories
-
RSS
Entries RSS
Comments RSS
